
















このブログ投稿のパート 1では、打ち切り売上確率分布を紹介しました。では実際に、有限容量が何を意味するのかを見てみましょう。まず、うっかり陥ってしまう可能性のある微妙な落とし穴を指摘し、次にその状況を私たちが通常どのように解決するかを共有します。
売上を需要と勘違いする
上司は、「最初のシンプルなモデル」と「モデル品質の大まかな見積もり」の両方を取得するために、このブログ投稿を完全に無視するように依頼するかもしれません。深呼吸してそうするかもしれません。つまり、販売数を真の需要として直接解釈するのです。
何が起こる可能性があるのでしょうか?偏りのない予測需要と観測された売上を単純に比較すると、通常、「予測は偏っていて、予測しすぎている」という判定が下されます。つまり、有限の容量によって観測された売上の値が低下したということです。定員に達する頻度が高ければ高いほど、売上への影響は大きくなります。実際には、特に有害なのは、有限の生産能力の影響が製品グループ間で大幅に異なることです。新鮮な製品は廃棄を避けるために時々在庫切れになる必要があり、生産能力が時々限界に達します。非腐敗性の商品は在庫切れになることなく補充されることが多く、容量が不足することはほとんどありません。製品グループ間の比較は、異なる生産能力/在庫増強戦略の影響が異なるため、大きな問題となります。
しかし、そもそも偏りのないモデルが得られるのでしょうか?それはありそうにありません。トレーニングでは、モデルは偏った需要を直接学習します。平均値が 9.7 の完全な需要分布のうち、モデルは制約付きの打ち切り分布のみを学習します。これは、下の図に示すように、平均値が低くなります。

予測の過小評価によって注文が少なくなり、在庫切れが増え、さらに予測が過小評価されるという悪循環が、評価で「すべて順調」かつ「売上予測は良好」と確認される一方で、永続的に加速していきます。他の状況では、トレーニングおよび評価フェーズ中の容量制約が何らかの理由で変化し、観察されたバイアス(またはその欠如)の解釈に悪影響を及ぼす可能性があります。
ここまで読んでいただければ、おそらく売上と需要は同等ではないことがおわかりでしょう。そして、より長く、より正確なルートを取るよう上司に説得力のある主張をすることができるでしょう。
需要が満たされなかった日を選択する
上記の落とし穴は非常に直感的です。需要と売上は異なる数量であり、等しくない場合にそれらを等しく設定するのは明らかに問題があります。皆さんに避けていただきたい 2 つ目の落とし穴は、もう少し微妙なものです (マネージャーに説明するために 2 時間の会議を予約してください)。プロジェクトでよく提案されるアイデアは、キャパシティー ヒットのないイベントのみ、つまり販売がキャパシティーを飽和させていない日にモデルをトレーニングまたは評価するというものです。つまり、打ち切りが行われたすべてのイベント(売上が在庫に等しい)はトレーニングまたは評価から削除され、容量よりも低い売上値のみが保持されます。残りのイベントは制約のないイベントであり、これによりトレーニングと評価が偏りのないものになることが期待されます。
しかし、これはまったく事実ではありません!容量に達しなかった日を選択することで、需要が偶然に特に小さくなったマイナスの変動イベントが自然に選択されます。つまり、負の外れ値であるイベントに焦点を当てることで、選択バイアスが導入されることになります。このようなトレーニング データセットや評価データセットは、実際の需要を偏りなく反映するのではなく、マイナスに偏った需要を生み出します。キャパシティーに達したイベントは、偶然の要因により、実際の需要が平均よりわずかに大きかったイベントです。全体的に偏りのない値を記録するためには、これらのイベントが必要になります。下の図では、キャパシティ ヒット イベントを削除すると、売上値のデータセット全体 (つまり、需要が制限されている) をトレーニングするよりも悪い結果になる可能性がある理由がわかります。キャパシティ ヒットしないことを条件とした平均売上 (緑の破線) は、全体の平均売上 (赤線) よりも低くなります。これは、キャパシティ ヒット時の平均売上 (黒線) がより高い値に寄与しているためです。覚えておいてください: 私たちが知りたい、または予測したいのは、青い点線で示した平均需要です。
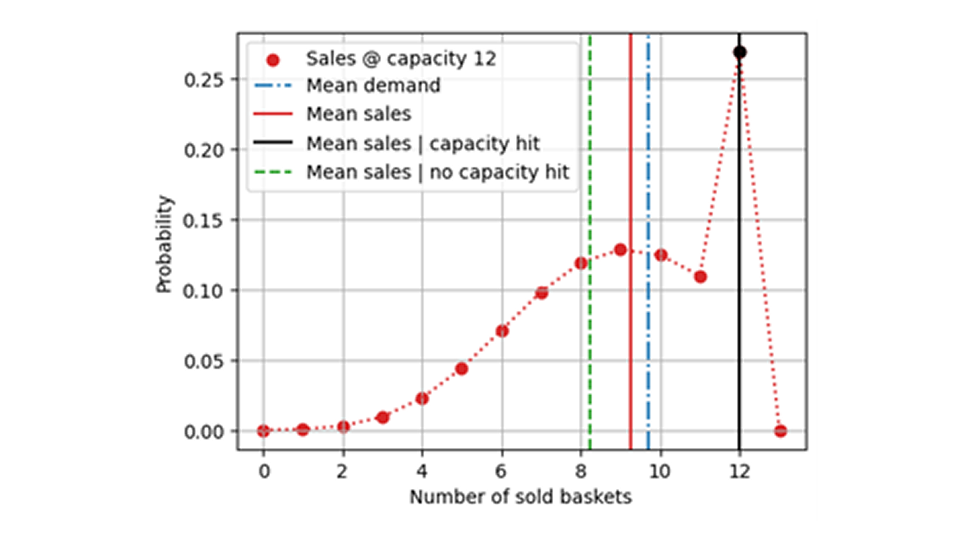
統計的に言えば、在庫切れがなかった日はすべての日を代表するわけではありませんが、スーパーマーケットに来る人が少なかった日です。イチゴが新鮮ではなかったのかもしれませんし、マンゴーのプロモーション キャンペーンが人々の興味をそそったのかもしれません。いずれにせよ、私たちは外れ値を選択することになり、それが偏りのないものであることを期待することはできません。
逆の戦略を採用し、キャパシティに達したイベントを選択した場合は、データセットにさらに強いバイアスがかかります。平均売上はキャパシティ設定戦略を正確に再現するため、予測とはまったく関係がなくなり、売上は常にキャパシティと一致するようになります。
評価データを「容量に達した」と「容量に達しなかった」で分けることは、予測評価の重要な原則の 1 つに違反します。予測の時点で不明な基準でデータを分割してはいけません。このような分割は、ほとんどの場合、結果として生じるグループに微妙な選択バイアスを引き起こします。同様の効果がブログ記事「You shouldn't have always know better」でも説明されています。
落とし穴を避ける方法
トレーニングに関しては、結論は悲惨です。キャパシティが 12 の場合に 12 を観測すると、その日の実際の需要の下限が設定されるだけであると説明するトービット回帰などの方法を使用した「適切な」トレーニングを避ける方法はありません。言い換えれば、12 個の商品が販売されるということは「12 個以上の商品の需要がある」ということを「理解する」回帰法が必要です。有限の容量はまさに情報を削除します。容量制約付きの販売を入力として使用するモデルは、正しく実行したとしても、制約のない需要を使用するモデルよりも常に精度が低くなります。
モデル評価では、有限の容量を明示的に考慮することができます。つまり、特定の有限の容量の下での予想売上高は、打ち切り確率分布から計算できます。繰り返しになりますが、キャパシティ制約下での予想売上高は、「制約のない需要予測」と「キャパシティ」のどちらか小さい方の値だけではなく、完全な制約付き確率分布を考慮する必要があることに注意してください。そして、次のような比較で終わります。
| 平均無検閲需要予測 | 平均打ち切り売上予測 | Mean actual sales |
| 17.84 | 14.35 | 14.66 |
この場合、実際の売上(容量制約後)が期待とよく一致していることが確認できます。
予測される容量ヒット確率と実際の容量ヒット頻度
キャパシティ制約下での予測売上と実際の売上を比較することは、予測の偏り(またはその欠如)を確立するのに役立ち、予測の質を確立するための良い第一歩となりますが、次のような懐疑的な意見に遭遇することもよくあります。「予測は全体的に偏りがないと認識していますが、残念ながら過剰予測と不足予測の両方が発生し、必要以上に無駄や在庫切れが発生するのではないかと懸念しています。」
言い換えれば、予測の利害関係者は、全体的な偏りがないことに関心があるだけでなく、あらゆる可能性のある需要状況における偏りがないことに関心があるのです。売上が非常に好調な日を過小に予測し、そのバランスを取るために売上の低い日を過大に予測することは望ましくありません。特に、キャパシティが限界に達した場合、関係者は限界がわずかにしか達しないこと(需要が満たされないまま去る顧客がほとんどいないこと)を確かめたいと考えます。無駄が生じる場合、莫大な量があってはなりません。
この正当な懸念に対処するために (全体的に偏りのないひどい予測によって多くの無駄と顧客の不満が生じることは容易に想像できます)、予測される容量ヒット確率ごとにデータを分離することを提案します。つまり、予測とその日に設置された特定の在庫レベルが与えられた場合、在庫が売り切れる予測確率、つまり予測容量ヒット確率を計算します。在庫レベルが予測に対して大きな値に設定されている場合、その容量ヒット確率は 0 に近くなります (たとえば、在庫レベルが需要分布の 0.99 分位に設定されている場合、容量レベルに達しないことが 99% 確実になります)。在庫レベルが小さい場合、たとえば需要分布の 0.01 分位に設定されている場合、容量ヒット確率は 1 に近くなります。
それぞれの予測について、容量に達すると予測される確率 (例: 0.42) と、実際の容量のヒット (ヒットまたはヒットなし) が得られます。このような単一のヒット / ノーヒット イベントは単なる逸話です。「予測された容量ヒット確率 = 0.05 だが、実際には容量がヒットした」といういくつかの「ありそうもない」ペアが存在するだけでは、予測確率が誤解を招くことを意味するものではありません。多数の確率予測とそれに関連するヒット/ノーヒットイベントのコレクションがある場合にのみ、予測された確率を厳密に検証できます。そのためには、容量ヒット確率 (0 から 1 までの浮動小数点数) と容量ヒット (個別の結果、「ヒット」の場合は 1、「ヒットしない」の場合は 0) のペアを多数収集します。これらを、予測される容量ヒットが約 0、約 0.10、約 0.20 などのバケットに分類します。次に、バケットごとに、予測された容量ヒット率と実際の容量ヒット率の平均を計算します。0.10 のケースで容量制限に達すると予測される場合、そのうちの約 10% のケースで実際に容量制限に達すると予想されます。
予測される 0.70 の容量ヒットが 70% のケースで発生するという意味で信頼できる場合、予測確率は「調整済み」と呼ばれます (調整の詳細については、ブログ記事「調整と鮮明度: 予測品質の 2 つの独立した側面」を参照してください)。調整された予測により、戦略的な補充決定を行うことができます。在庫レベルを、0.023 日で在庫切れになることが予想されるように設定すると、実際に在庫切れになるのは 2.3% の日数になります。これがリスク管理です。リスクを慎重に定量化し、取る価値のあるリスクを意識的に取ります。
下の図では、黒い円は個々の容量ヒット イベントを示しています。容量がヒットしたか (図の上部)、ヒットしなかったか (図の下部) を示しています。すべての予測をグループ化すると、平均予測容量ヒット率 0.82 が測定された頻度 (緑色の円) と一致します。容量ヒット確率が 0、0.1、0.2 などに近い順に分類すると、容量ヒット予測が調整されていることがわかります。青い円は対角線に近くなります。
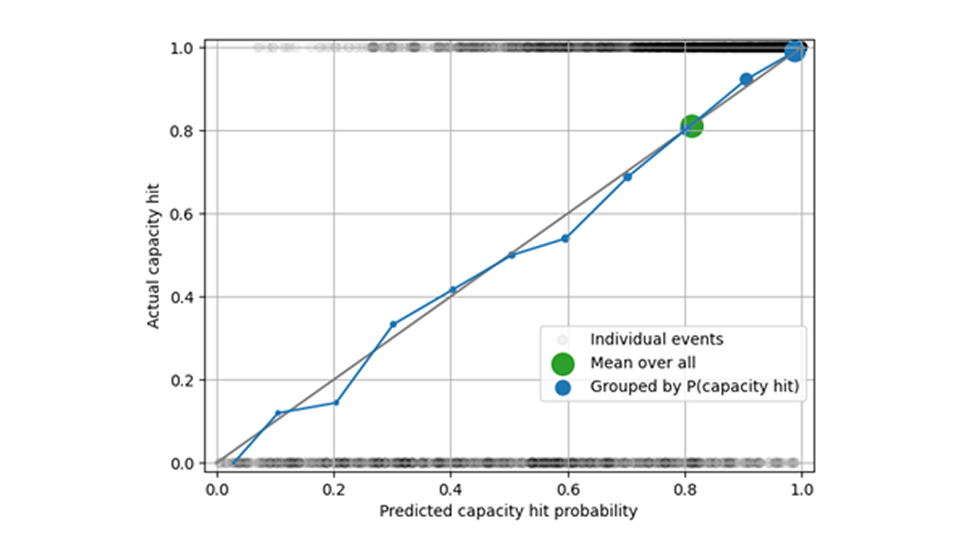
予測された容量ヒットの確率と頻度を実際の容量ヒットの確率と頻度と比較して評価するだけでは、適切な予測を確実に行うには不十分です。1,000 個のアイテムを在庫する場合、予測数が 5、10、または 100 のいずれであっても、容量ヒットの動作に違いはありません。すべてのケースで、イベントは「容量は確実にヒットしない」という同じバケットに収まります。したがって、予測される売上全体の偏りの分析は、キャパシティヒット率の分析を補完し、予測がキャパシティ制約と速度の両方にわたって偏りがないことを確認する必要があります。
一般的に、予測されるキャパシティヒット確率または予測される売上高によるグループ化は、「過去を振り返るのではなく、将来を見据えて予測を評価する」というルールに従っており、ブログ記事「常にもっとよく知っておくべきだったわけではない」で説明されている後知恵バイアスを回避します。
結論:リスク管理には確率論的ツールが必要
予測として単一の数値を生成するポイント予測は、在庫切れ率を 1% 未満に抑えることができる在庫レベルなど、戦略的な確率の問題に対処するのに適していません。確率的な質問をする場合(リスクに関する質問はすべて確率的です)、その質問に答えるには確率的なツールが必要です。マネージャーには、少なくとも「期待値」、「打ち切り」、「分布」の基本的な理解を教える必要があるでしょう。
容量が現実世界に影響を与えるときはいつでも(そしてほとんどの場合影響を与えます)、容量の制約を真剣に受け止める必要があります。事後的に事象を理解しようとするのではなく(「その日にキャパシティが限界に達したのですが、正確な原因は何だったのでしょうか?」)、将来を見据えて、予測される売上と予測されるキャパシティ限界到達確率ごとに予測を分類し、予測の調整を評価する必要があります。
このブログ投稿のすべての例は、適切な分布を生成する完璧な需要予測を前提として、サンドボックスのような環境で構築されました。私は、現実世界で通常遭遇するより複雑な問題すべてからあなたを守りました。それでも、この単純なシナリオでも、私たちの直感がいかに簡単に騙されるかが分かります。したがって、評価の問題を解決する方法として最初に思いついたアイデア(「容量がヒットしたかヒットしなかったかでグループ化しましょう」)にただ従うのではなく、懐疑的な視点を取り入れ、まず理想的な設定でその方法がどのような効果をもたらすかをシミュレートすることが重要です。
