良い予測とは何でしょうか?
予測は友人のようなものです。信頼が最も重要な要素です (友人に嘘をつかれたくはありません)。しかし、信頼できる友人の中でも、最も興味深い話をしてくれる友人に会いたいものです。
この比喩で何を意味しているのでしょうか?私たちが求めているのは、「良い」「正確」「精密」な予測です。しかし、それはどういう意味でしょうか?予測から何を得たいのかをより明確に表現し、視覚化するために、思考を研ぎ澄ましましょう。予測の品質を測定する方法は 2 つあり、予測のパフォーマンスを十分に理解するには、調整と鮮明さの両方を考慮する必要があります。
予測の調整
簡単にするために、バイナリ分類から始めましょう。予測される結果は、「真または偽」、「0 または 1」などの 2 つの値のみを取ることができます。
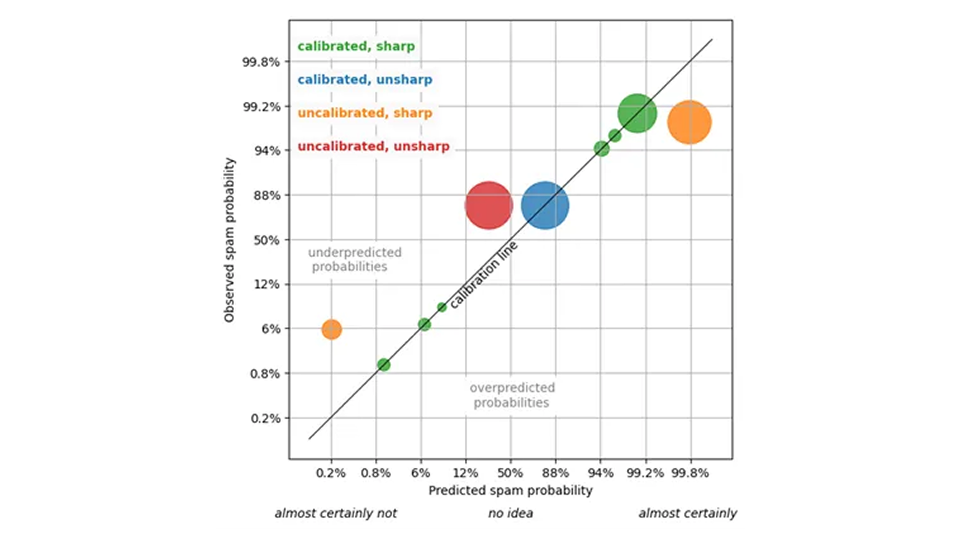
より具体的には、電子メールがメールボックス ユーザーによってスパムとしてタグ付けされるかどうかについて考えてみましょう。予測システムは、各電子メールについて、その電子メールがユーザーによってスパムであると判断される確率(これを真実と見なします)をパーセンテージで算出します。一定のしきい値(たとえば 95%)を超えると、電子メールはスパム フォルダーに送られます。
このシステムを評価するには、まず予測の調整を確認します。80% のスパム確率が割り当てられた電子メールの場合、実際のスパムの割合は約 80% になるはずです (または少なくとも統計的に有意な差はありません)。スパム確率が 5% と割り当てられた電子メールの場合、実際のスパムの割合は約 5% になるはずです。そうなれば、予測を信頼することができます。つまり、5% の確率と言われているものは、実際に 5% の確率です。
調整された予測により、戦略的な決定を下すことができます。たとえば、スパム フォルダーのしきい値を適切に設定し、誤検知/誤検出の数を事前に見積もることができます (一部のスパムが受信トレイに届き、一部の重要なメールがスパム フォルダーに入ってしまうことは避けられません)。
予測の鮮明さ
品質を予測するには調整だけが必要なのでしょうか?そうでもないよ!すべての電子メールに全体的なスパム確率(85%)を割り当てる予測を想像してください。すべての電子メールの 85% がスパムまたは悪意のあるものであることから、この予測は正確に算出されています。この予測は信頼できます。嘘をついているわけではありませんが、まったく役に立ちません。「このメールがスパムである確率は 85% です」という些細な繰り返しの言葉に基づいて、有益な判断を下すことはできません。
役に立つ予測とは、さまざまな電子メールに非常に異なる確率を割り当て、上司からの電子メールがスパムである確率を 0.1%、疑わしい医薬品広告の確率を 99.9% に設定し、調整されたままにする予測です。この有用性の特性は、予測が与えられた場合に予測される結果の分布の幅を指すため、統計学者によって「シャープネス」と呼ばれています。幅が狭いほど、シャープになります。
常に 85% のスパム確率を生成する非個別化予測は、最大限に不鮮明です。最大シャープネスとは、スパム フィルターがすべての電子メールに 0%または100% のスパム確率のみを割り当てることを意味します。この最大限の鮮明さ、つまり決定論は望ましいものですが、非現実的です。このような予測は(おそらく)調整されず、スパム確率 0% とマークされたメールの中にはスパムであるものもあれば、スパム確率 100% とマークされたメールの中にあなたの大切な人からのメールであるものもあるでしょう。
では、最も良い予測は何でしょうか?私たちは信頼を手放したくないので、予測は調整されたままにしておく必要がありますが、調整された予測の中でも最も正確な予測を求めています。これは、2007 年に Gneiting、Balabdaoui、Raftery によって策定された確率予測のパラダイムです (J.R. 国家主義者。社会B 69、パート2、pp.243~268):シャープネスを最大化しますが、キャリブレーションを危険にさらさないでください。それが真実である限り、可能な限り最も強い声明を出してください。私たちの友達と同じように、私に最も興味深い話をしてください。ただし、私に嘘をつかないでください。スパム フィルターの場合、最も正確な予測では、明らかにスパムではないメールには 1%、明らかにスパムであるメールには 99%、判断が難しいケース (あまり多くないはず) には中間の値などが割り当てられます。