
















ジェネレーティブAIがサプライチェーンでの働き方をどのように変えるかについては、多くの議論がなされてきました。Blue Yonderでは、ベンチマーク調査を通じてこれらの影響を調査したいと考えました。私たちの研究実験では、大規模言語モデル(LLM)がすぐに使える能力と、サプライチェーン分析に効果的に適用して、サプライチェーン管理で直面する実際の問題に対処できるかどうかを調査しました。
ChatGPTを含むLLMは、大量のデータで訓練された人工知能の一種であり、言語のパターン、文法、意味を学習することができます。過去数年間で、LLMは爆発的な成長を遂げ、 コンテンツ作成、カスタマーサービス、市場調査など、世界中のさまざまなアプリケーションで使用されています。
IDCのデータによると、ソフトウェア・情報サービス、銀行、小売業界は 、2024年に約896億ドルをAIに割り当てると予測されており、ジェネレーティブAIは総投資額の19%以上を占めています。
この急速に進化するテクノロジーは、企業に創造性、効率性、意思決定能力の向上をもたらし、業界とプロセスに革命を起こす力を持っています。では、LLMは現在、サプライチェーンの状況にどのように対処しているのでしょうか?
Blue YonderのジェネレーティブAIベンチマーク調査について
当社のジェネレーティブAIサプライチェーンテストは、Uniform Bar Examinationと呼ばれる バイラルなChatGPT実験 に大まかに基づいています。この調査では、ChatGBTの最新バージョンが司法試験に合格し、合計スコアが297点と高く、全受験者の90パーセンタイルに近づいています。LLMは、ほぼ上位10%のスコアでバーを通過することにより、ジェネレーティブAIが法的原則と規制を理解して適用する能力を示しています。この画期的な研究は、世界的な議論を巻き起こし、AIの変革の可能性を浮き彫りにしました。
Blue Yonderは、この会話をさらに一歩進めて、主要なLLMシステムがサプライチェーン業界の試験でどのように機能するかを研究することにしました。LLMは、 CPSM と CSCPの2つの標準認証テストと対決しました。私たちの目標は?LLMがサプライチェーンの専門家として機能し、トレーニングなしでサプライチェーン業界のニッチなルールとコンテキストを理解できるかどうかを確認するため。
この実験は、各LLMを模擬テストを通じてプログラム的に実行するように設計されており、テストに関するコンテキストはなく、インターネットへのアクセスも、コーディング機能もありません。私たちは、LLMが箱から出してすぐにどのように機能するかを評価し、一貫性のある偏りのない評価を可能にしたいと考えました。
CPSMとCSCPの両方の認定テストは多肢選択式です。LLMが単に答えを選択するのではなく、モデルが選択した各選択肢を説明するための出力を設定します。このアプローチにより、各モデルの推論プロセスについて貴重な洞察を得ることができ、なぜ答えが間違っているのか、または正しいのかを理解することができ、各モデルの能力を評価するのに役立ちました。
LLM の更新バージョンがリリースされた後、新しいベンチマーク結果を集めるために、今年の夏に再度テストを実行しました。
では、LLMはサプライチェーン試験に合格できるのでしょうか?
印象的なことに、LLMは、トレーニングなしでサプライチェーン試験で驚くほど優れた成績を収めました。まず、LLMのすぐに使えるパフォーマンスをコンテキストなしで確認し、次にいくつかの利点を追加しました。
ステージ1:コンテキストなし、インターネットアクセスなし、コーディング能力なし
ほとんどのモデルが文脈なしで堅実な合格点を達成した一方で、Claude 3.5 Sonnetは際立っており、CPSM認定テストで79.71%という驚異的な精度を確保しました。CSCP試験では、OpenAIのo1-PreviewモデルとGPT 4oモデルがClaude Opusを上回り、Claude Opusの45.7%に対して48.30%の精度を獲得しました。
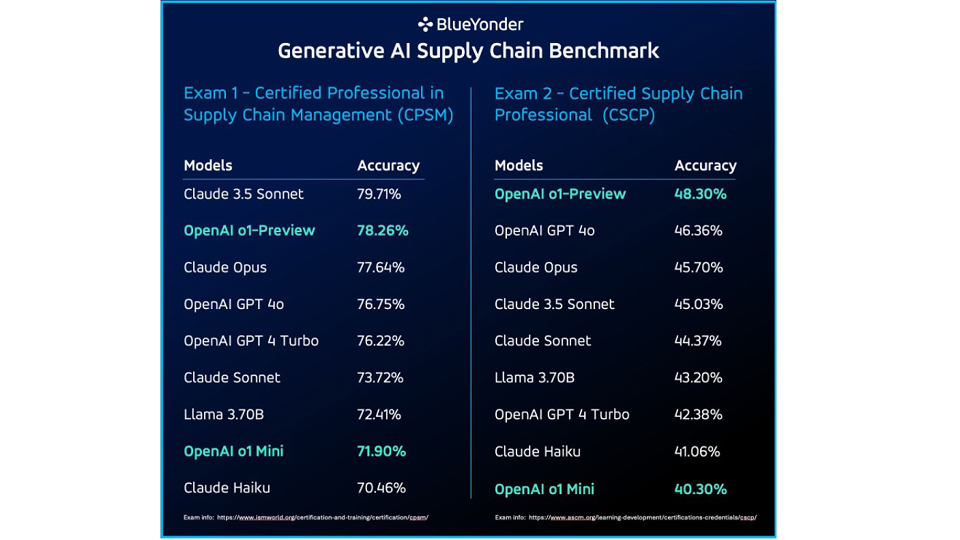
LLMは特定の分野で優れたパフォーマンスを発揮しましたが、特に数学関連の質問や深くドメイン固有の問題に直面した場合には、制限も示しました。
各認定試験で数学の問題のみを調べた場合、OpenAI o1 Miniは、テストされたClaudeモデルよりも優れたOpenAIモデルの精度が大幅に向上したことを示しました。

これらの結果は、コンテキスト、インターネットアクセス、コーディング能力がないという条件で生成されました。次に、LLMにもっと支援を提供し始めたらどうなるかを探りました。
ステージ 2: インターネット アクセスの追加
テストの次の段階では、LLMプログラムにインターネットへのアクセスを提供し、you.com を使用して検索できるようにしました。この追加機能により、OpenAI GPT 4 Turbo は CSCP テストで 42.38% から 48.34% へと最も大きな進歩を達成しました。
最初のコンテキストなしテストで最初に見落とされた問題を見ると、Claude Sonnetモデルは、CPSMの質問で約53.84%、CSCPの質問で約20%の精度評価を達成しました。
インターネットアクセスにより、モデルは独立して情報を検索できましたが、信頼性の低いオンライン情報源による不正確さの可能性ももたらしました。
ステージ3:RAGによるコンテキストの提供
次のテストでは、RAG(retrieval augmented generation)モデルを使用し、LLMにテストの学習資料を提供しました。RAGを使用すると、LLMSは非数学的な問題でノンコンテキストテストとオープンインターネットアクセステストの両方を上回り、両方のテストで最高の精度スコアを達成しました。
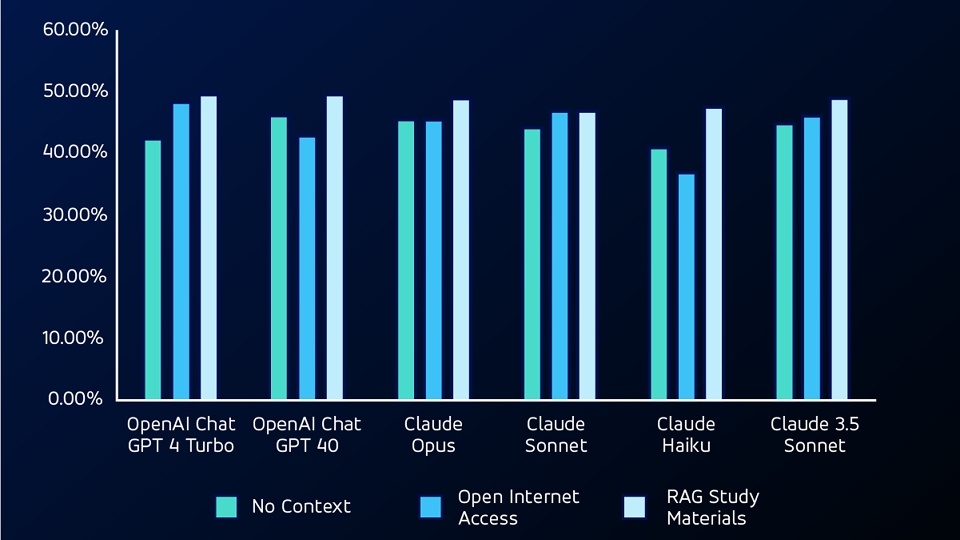
ステージ4:コーディング能力の追加
最後に、次のテストでは、Code Interpreter フレームワークと Open Interpreter フレームワークを使用して、モデルが独自のコードを記述して実行できるようにしました。
これらのフレームワークを使用して、LLMは、テストの最初の反復で苦労した試験の数学的問題を解決するのに役立つコードを書くことができました。コーディング能力により、LLMは、数学の問題のすべてのモデルで平均約28%の精度で、コンテキストなしテストを上回りました。
LLMはサプライチェーンの問題を解決するのに役立ちますか?
全体として、LLMシステムは業界標準のサプライチェーン試験に合格しました。このパフォーマンスは、LLMをサプライチェーン管理に統合するための非常にエキサイティングな可能性を示しています。ただし、モデルはまだ完璧ではありません。彼らは、数学の問題と特定のサプライチェーンロジックの両方に苦労していました。
コードを書く能力が追加されたことで、LLMは数学の問題の多くを克服することができましたが、試験内のより複雑な問題のいくつかを解決するために、非常に具体的なサプライチェーンのコンテキストが必要でした。
私たちの研究で明らかになったのは、ジェネレーティブAIは、適切なツールとトレーニングにより、サプライチェーンの問題を解決するのに非常に役立つ可能性があるということです。
幸いなことに、それがBlue Yonderの得意とするところです。私たちは、ジェネレーティブAIの力を活用して、サプライチェーンの課題に対する実用的で革新的なソリューションを生み出すことに尽力しています。新たにリリースされた AI Innovation Studio は、これらのソリューションを開発するためのハブであり、複雑な AI テクノロジーと現実世界のアプリケーションとの間のギャップを埋めます。
私たちは、サプライチェーン内の特定の役割に合わせたインテリジェントなエージェントを作成し、これらのエージェントが現在直面している実際の問題や課題を解決するための体制を整えることに重点を置いています。Blue YonderのAIと機械学習の詳細をご覧いただくか、1対1の会話を開始するためにお問い合わせください。
